네 번째 프로젝트 회고 - LXP 프로그래밍

🥑 들어가며
세 번째 프로젝트에서 공들여 구현했던 모놀리식 멀티모듈 서버를 이번에 MSA(Microservices Architecture)로 전환하는 대수술을 진행했다. 단순히 공부를 넘어 실무적인 감각을 익히고 싶었기에, 실제 현업에서 마주할 법한 문제들을 시뮬레이션하며 꽤 설레는 마음으로 시작했다.
DB까지 완전히 분리하고 싶은 욕심도 있었지만, 첫 MSA 도전인 만큼 관리의 복잡성과 정합성 문제를 고려해 이번 단계에서는 서비스 계층의 완전한 분리와 통신 아키텍처 수립에 집중하기로 결정했다.
📌 구현 사항: 모놀리식에서 MSA로의 여정
가장 큰 도전은 기존 모놀리식 멀티 모듈 구조를 도메인별 서비스로 분리하는 것이었다. 나는 User 및 Auth 도메인을 담당하며 전체 시스템의 관문인 API Gateway를 함께 구축하게 되었다.
Passport 정책: 분산 환경에서의 인증과 신뢰
MSA 구조에서는 각 마이크로서비스가 매번 인증 서버에 사용자 정보를 묻지 않고도 신뢰할 수 있는 정보를 전달받는 것이 중요했다. Netflix의 Passport 개념을 차용하여 다음과 같은 보안 전략을 수립했다.
- 이중 토큰 전략:
- 외부(Client ↔ Gateway): 비대칭키 방식의 AccessToken을 사용하여 보안성을 확보.
- 내부(Gateway ↔ Service): 서비스 간 통신 성능을 위해 대칭키 기반의 내부 전용 JWT인 ‘Passport’를 사용. 단순 객체 직렬화가 아닌 JWT 서명을 활용하여 내부 네트워크에서의 위변조 가능성을 차단.
- 컨텍스트 전파 및 추적:
- Passport 내부에는 유저 정보뿐만 아니라 traceId를 포함.
- 각 서비스의 Filter에서 이를 파싱해
SecurityContext에 등록하고,MDC에 traceId를 설정하여 분산 환경에서도 하나의 요청에 대한 전체 로그를 추적할 수 있도록 설계.
🔄 전체 인증 및 호출 흐름 (Sequence Diagram)
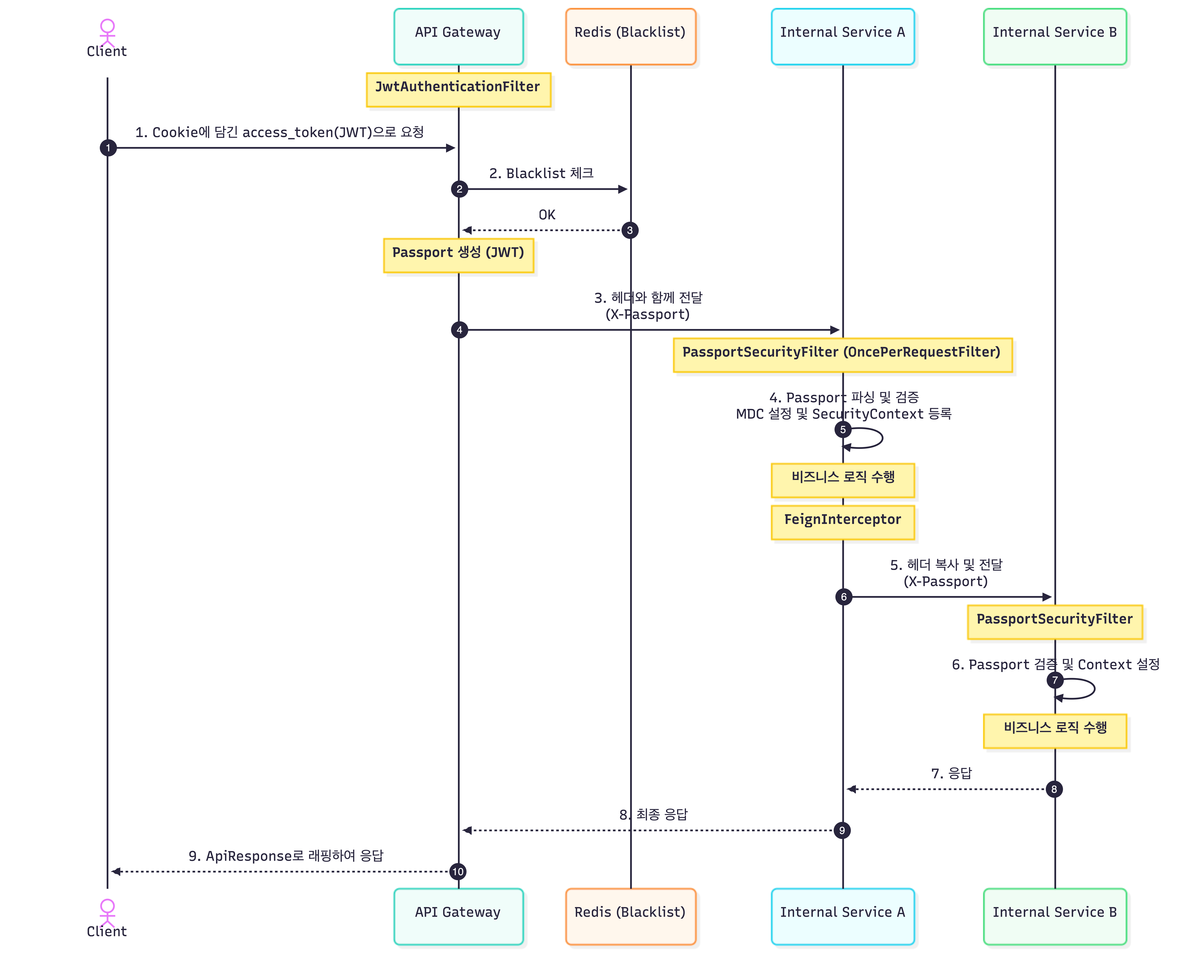
클라이언트 요청 및 1차 검증: 사용자가 쿠키에 담긴 access_token으로 요청을 보내면, API Gateway가 이를 수신하여 Redis를 통해 블랙리스트 여부를 즉시 확인한다.
- 내부용 Passport 토큰 발급: 검증이 완료되면 Gateway는 내부 서비스 간 통신에 사용할 내부 전용 JWT인 ‘Passport’를 생성한다. 이 Passport 내부에는 유저 정보와 함께 요청 추적을 위한 traceId가 포함된다.
내부 서비스로의 전파: 생성된 Passport는 X-Passport 헤더에 담겨 서비스 A로 전달된다. 서비스 A의 Security Filter는 이 토큰을 파싱하여 SecurityContext에 유저 정보를 등록하고, 토큰 안의 traceId를 꺼내 MDC에 설정함으로써 로그 추적 환경을 구축한다.
- 서비스 간 연쇄 호출 (Feign): 서비스 A가 서비스 B를 호출할 때, FeignInterceptor가 현재 스레드의 Passport를 그대로 복사하여 전달한다. 서비스 B 또한 동일한 필터 로직을 통해 인증과 로그 추적 상태를 유지한다.
- 응답 처리 및 최종 래핑: 모든 비즈니스 로직이 완료되어 데이터가 Gateway로 돌아오면, Gateway는 이를 ApiResponse 규격으로 최종 래핑하여 클라이언트에게 일관된 형식으로 응답한다.
협업을 위한 정책 문서화와 가이드 배포
MSA로 서비스가 파편화되면서, 각 도메인 담당자들이 새로운 인증 정책을 오해 없이 구현하는 것이 숙제였다. 이를 위해 단순 구두 전달이 아닌 공통 정책 문서화 작업을 선행했다.
- GitHub Discussions 활용: [Passport 구현 가이드 v0.1.0]과 [Passport 정책]을 작성하여 팀 내 공유했다.
- 버전 관리와 명세화: Gateway에서 전달되는
X-Passport헤더의 상세 규격, JWT Claim 구조, 그리고 각 서비스의 필터에서 이를 어떻게 처리해야 하는지 단계별 가이드를 제공했다. - 결과: 덕분에 서비스 담당자가 바뀌거나 새로운 서비스가 추가되어도 일관된 인증 로직을 유지할 수 있는 기반을 마련했다.
[관련 문서 링크]
비동기 메시징과 시스템 가용성 확보
서비스 간 강결합을 해소하고, 특정 서비스의 장애가 전체로 번지는 것을 막기 위해 RabbitMQ와 Resilience4j를 도입했다.
1. RabbitMQ를 활용한 이벤트 기반 아키텍처
User 서비스에서 프로필 수정 등의 이벤트가 발생하면 RabbitMQ를 통해 연관 서비스로 데이터를 전파한다.
응답 속도가 중요한 API 호출 과정에서 부가적인 데이터 동기화 로직을 분리함으로써 시스템 전반의 응답 성능을 개선하고 서비스 간 의존성을 낮췄다.
2. Circuit Breaker를 통한 장애 전파 방지 (Resilience4j)
결함 내성(Fault Tolerance): 특정 서비스(예: 외부 API 연동 부)에 장애가 발생하거나 응답이 지연될 때, Resilience4j를 사용하여 서킷을 개방(Open)하도록 설정했다.
Fallback 처리: 서비스 호출 실패 시 무작정 대기하거나 에러를 뱉는 대신, 미리 정의된 Fallback 로직(캐시 데이터 반환 또는 기본값 응답)을 수행하게 하여 사용자 경험의 단절을 최소화했다.
✨ 느낀 점
MSA라는 거대한 바다에 뛰어들어보니, 설계 당시에는 미처 몰랐던 현실적인 벽들과 마주할 수 있었다. 이번 프로젝트를 통해 느낀 아쉬운 점들을 정리하며 다음 스텝을 기약해 보려한다.
서비스 분리의 역설: 관리의 복잡성
도메인별로 서비스를 세밀하게 나누다 보니, 역설적으로 시스템 전체가 너무 비대해졌다. 로컬에서 여러 서버를 동시에 띄우는 것부터 시작해, 각 서비스의 의존성 관리와 배포 환경 설정이 기하급수적으로 힘들어지는 것을 경험했다.
무조건 쪼개는 것이 정답이 아닌, 서비스 간의 경계를 정할 때는 관리 비용과 복잡성을 반드시 우선순위에 두어야 함을 깨달았다.
관측 가능성(Observability)의 부재
MSA로 전환하면서 가장 뼈아프게 다가온 것은 ‘로깅과 모니터링’이었다. 여러 서버를 넘나드는 요청의 흐름을 텍스트 로그만으로 파악하기엔 한계가 명확했다.
Prometheus와 Grafana를 도입하여 서버의 리소스 상태와 트래픽 지표를 시각화했다면, 혹은 Zipkin 같은 분산 추적 시스템을 더 깊게 활용했다면 훨씬 견고한 시스템이 되었을 것 같다. ‘살아있는 서버’를 관리하기 위해 로깅은 선택이 아닌 필수임을 배웠다.
설정 관리의 번거로움: Config Server의 필요성
각 서비스마다 중복되는 설정값들과 변경될 때마다 매번 다시 빌드해야 하는 번거로움을 겪으며, Spring Cloud Config의 부재가 크게 느껴졌다. 설정 정보를 중앙에서 관리하고 런타임에 반영할 수 있는 구조가 MSA 운영에 얼마나 큰 편리함을 주는지 간접적으로 체감할 수 있었다.
💡 새로운 고민: 중복 코드와 공통 라이브러리의 필요성
정책을 문서화하고 각 서버에 적용하다 보니 또 다른 문제에 직면했다. Passport를 파싱하고, SecurityContext에 담고, Feign 호출 시 헤더를 복사하는 로직이 모든 마이크로서비스에 중복으로 존재하게 된 것이다.
이로 인해 정책이 v0.2.0으로 업데이트될 경우, 모든 서비스의 코드를 일일이 수정해야 하는 비효율이 예상되었습니다. 이를 해결하기 위해 “공통 인증 라이브러리(Custom Starter)”를 직접 만들어 배포하고 싶다는 강한 니즈를 느꼈다.
단순히 코드를 복사하는 것이 아니라, 스프링 부트의 Auto-configuration 기능을 활용해 의존성만 추가하면 자동으로 인증 로직이 주입되는 구조를 구상하게 된 계기가 되었다.
백엔드 개발자와 DevOps, 그 사이의 경계
이번 프로젝트에서 Minikube를 통해 쿠버네티스 환경을 경험해 보았다. 비록 내가 인프라를 직접 밑바닥부터 구축한 것은 아니었지만, 우리가 짠 코드가 컨테이너화되어 오케스트레이션되는 과정을 지켜보는 것만으로도 큰 공부가 되었다.
여기서 한 가지 근본적인 질문이 생겼다. “백엔드 개발자는 어디까지 인프라를 알아야 할까?” 결론적으로, 단순히 ‘사용할 줄 아는 것’ 이상의 지식이 필요하다고 생각한다. 내가 만든 코드가 클라우드 환경에서 어떻게 배포되고, 리소스가 어떻게 할당되며, 네트워크가 어떻게 연결되는지 이해해야만 ‘인프라 친화적인 최적화된 코드’를 짤 수 있기 때문이다.
백엔드 개발자가 쿠버네티스를 직접 구축할 필요는 없지만, 내 앱이 쿠버네티스에서 ‘왜’ 죽었는지 로그를 보고 진단할 줄은 알아야 하는 것 같다.
맺으며
MSA는 단순히 기술적인 유행이 아니라, 조직과 서비스의 규모에 맞는 트레이드오프(Trade-off)의 산물이라는 것을 배웠다. 비록 모든 것을 완벽하게 구현하지는 못했지만, “왜 이 기술이 필요한가?”에 대한 답을 몸소 겪으며 찾아낸 귀중한 시간이었다.